
CogVideoX – 智谱AI推出的开源AI视频生成模型

CogVideoX是什么
CogVideoX是智谱AI最新推出的开源AI视频生成模型,与智谱AI的商业产品同源。
CogVideoX支持英文提示词,能生成6秒长、每秒8帧、分辨率为720*480的视频。模型推理需16-36GB显存,目前不支持量化推理和多卡推理。项目还包括3D Causal VAE组件用于视频重建,以及丰富的示例和工具,包括CLI/WEB Demo、在线体验、API接口示例和微调指南。

CogVideoX的主要功能
AI文生视频:支持用户输入的文本提示词生成视频内容。
高显存需求:推理过程需要较高的GPU显存支持,优化前使用diffusers为36GB,使用SAT为16GB。
视频参数定制:可以定制视频长度、帧率和分辨率,目前支持6秒长视频,8帧/秒,分辨率为720*480。
3D Causal VAE技术:使用3D Causal VAE技术,实现视频内容的高效重建。
推理与微调:模型支持基本的推理生成视频,同时提供了微调能力,以适应不同需求。
CogVideoX的技术原理
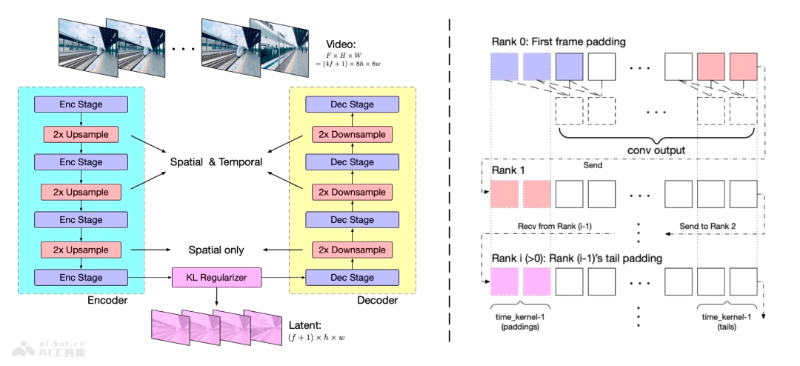
- 文本到视频生成:CogVideoX使用深度学习模型,特别是基于Transformer的架构,来理解输入的文本提示并生成视频内容。
- 3D Causal VAE:CogVideoX采用了3D Causal Variational Autoencoder(变分自编码器),一种用于视频重建和压缩的技术,能够几乎无损地重构视频,减少存储和计算需求。
- 专家Transformer:CogVideoX使用专家Transformer模型,一种特殊的Transformer,通过多个专家处理不同的任务,例如空间和时间信息的处理,以及控制信息流动等。
- 编码器-解码器架构:在3D VAE中,编码器将视频转换成简化的代码,而解码器根据这些代码重建视频,潜在空间正则化器确保编码和解码之间的信息传递更准确。
- 混合时长训练:CogVideoX的训练过程采用混合时长训练,允许模型学习不同长度的视频,提高泛化能力。
- 多阶段训练:CogVideoX的训练分为几个阶段,包括低分辨率预训练、高分辨率预训练和高质量视频微调,逐步提升模型的生成质量和细节。
- 自动和人工评估:CogVideoX使用自动评估和人工评估相结合的方式,确保生成的视频质量达到预期。
CogVideoX的项目地址
- 智谱清影体验:https://ai-bot.cn/chatglm-video/
- GitHub仓库:https://github.com/THUDM/CogVideo
- HuggingFace模型库:https://huggingface.co/THUDM/CogVideoX-2b
- 技术报告:https://github.com/THUDM/CogVideo/blob/main/resources/CogVideoX.pdf
- arXiv技术论文:Coming soon
CogVideoX的性能评估
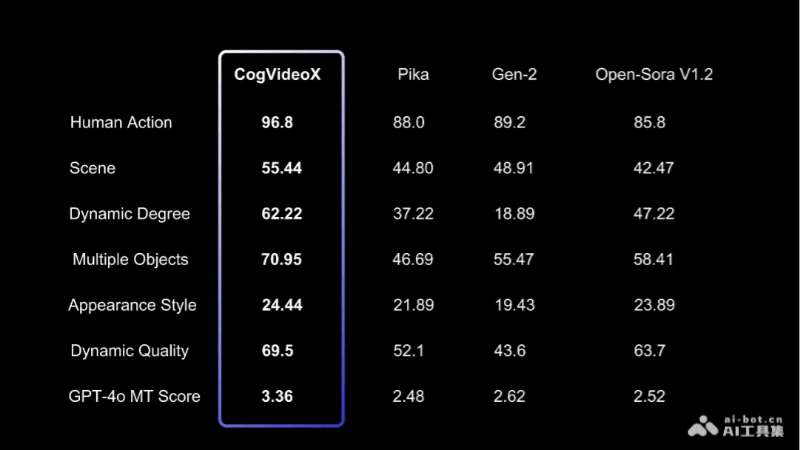
为了评估文本到视频生成的质量,我们使用了VBench中的多个指标,如人类动作、场景、动态程度等。我们还使用了两个额外的视频评估工具:Devil 中的 Dynamic Quality 和 Chrono-Magic 中的 GPT4o-MT Score,这些工具专注于视频的动态特性。如下表所示。
CogVideoX的应用场景
- 创意视频制作:为独立视频创作者和艺术家提供工具,快速将创意文本描述转化为视觉视频内容。
- 教育和培训材料:自动化生成教育视频,帮助解释复杂概念或展示教学场景。
- 广告和品牌宣传:企业可以用CogVideoX模型根据广告文案生成视频广告,提高营销效果。
- 游戏和娱乐产业:辅助游戏开发者快速生成游戏内动画或剧情视频,提升游戏体验。
- 电影和视频编辑:辅助视频编辑工作,通过文本描述生成特定场景或特效视频。
- 虚拟现实(VR)和增强现实(AR):为VR和AR应用生成沉浸式视频内容,增强用户互动体验。
Comments
Tiffany West
Sat, 10/28/2017 - 21:43 ReplyRyan Gosling
Thu, 06/27/2024 - 22:33 ReplyVestibulum sit amet vehicula justo. Nam consequat vulputate lorem, vitae imperdiet est posuere fermentum. Nunc tempus in magna eget venenatis. Proin libero lorem, efficitur et sem sed, ullamcorper maximus velit.